MySQL基础
该文章持续更新中…
环境声明
- 系统: Windows10家庭中文版
- 硬件: 16G内存、8核CPU
- 集成环境: 小皮面板8.1.1.3
- Mysql版本: 5.7.26
- 强烈推荐学习视频: B站-Java酱
概念
数据库
数据库
连接数据库
本地数据库
1 | # 连接数据库 |
1 | C:\Users\king>mysql -u root -p |
远程数据库
1 | # 语法 |
1 | C:\Users\king>mysql -h 192.168.2.100 -u root -proot |
远程连接失败时
本地登录到数据库后,查询需要登录的用户是否允许远程登录,host为%时允许远程登录
1 | mysql> select host,user from mysql.user where user='root'; |
1 | C:\Users\king>mysql -h 192.168.2.100 -u root -proot |
将需要登录的用户host改为%,并且使用flush privileges刷新权限后再登录
1 | mysql> update mysql.user set Host='%' where user='root' and host='localhost'; |
创建数据库
语法
-> 关于Mysql数据库字符集字符集 <-
1 | -- 创建数据库 |
1 | -- 查询数据库信息 |
创建示例
1 | -- 创建new_sql数据库,判断是否存在,并指定字符集为utf8 |
修改数据库
语法
1 | -- 修改数据库的字符集 |
修改示例
1 | -- 将new_sql数据库的字符集改为gbk |
选择数据库
语法
1 | -- 选择需要操作的数据库 |
选择示例
1 | -- 选择mysql数据库 |
删除数据库
语法
1 | -- 删除数据库 |
删除示例
1 | mysql> drop database new_sql; |
数据类型
下方表格来源: 菜鸟教程-Mysql教程
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期时间类型
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串(动态分配) |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
数据表
创建数据表
语法
1 | -- 创建数据表 |
1 | -- 查看数据表 |
创建示例
id字段(列)类型为int,not null表示值不能为NULL空值,AUTO_INCREMENT表示字段自增长username字段类型为varchar(20),最大字符个数为20,not null表示值不能为NULL空值email字段类型为varchar(20),最大字符个数为20,值可以为空PRIMARY KEY (id)表示该表的主键为字段id
1 | -- 创建一个名为new_sql的数据库 |
修改数据表
语法
1 | -- 修改表名 |
修改表名
1 | -- 将users表名修改为user_info |
修改表字符集
1 | -- 将user_info表的字符集修改为utf8 |
添加字段(列)
1 | -- 为user_info表添加一个字段,字段名为age,数据类型为int |
修改字段名
1 | -- 将user_info表的age字段名修改为sex,且数据类型修改为char(2) |
修改字段数据类型
1 | -- 将user_info表的sex字段数据类型修改为int |
删除字段
1 | # 删除user_info表的sex字段 |
删除数据表
语法
1 | -- 删除数据表 |
删除示例
1 | -- 删除user_info数据表 |
插入数据
注意
- 字段和值要一一对应
- 表名后不指定字段则表示给所有列添加值
- 除了数字类型,其他类型需要使用引号包裹数据(标准使用单引号)
- 当有自增长的字段时,可以不用插入数据
- 字段为
not null时不允许不插入数据
语法
1 | -- 插入数据 |
插入示例
1 | -- users表信息 |
1 | -- 插入一行数据,每个字段与值一一对应 |
简单查询
语法
1 | select 字段1,字段2 from 数据库名.表名 -- 未选择数据库或查询其他数据库时使用 |
查询示例
1 | -- 只查询users表的id与username字段的数据 |
1 | -- 查询users表的所有字段 |
修改数据
语法
1 | -- 将指定字段的所有值都改成指定值(不指定条件则修改全部) |
修改示例
1 | -- 创建销售记录表并插入数据 |
1 | -- 将name字段的小陈改成小张 |
1 | -- 将name字段的所有数据都改成小红 |
删除数据
语法
1 | -- 删除所有值(清空表) |
删除示例
1 | -- 删除sales_records表下id字段为1的一行数据 |
条件查询
指定别名
语法
- 当表名很长或执行特殊查询时,为方便操作可以为表或字段指定别名,用别名代替原来的表或字段名
- 表的别名不能与该数据库其他表同名,字段的别名不能与该表其他字段同名
- 在条件表达式中不能使用字段的别名,否则会报错
- 表的别名只在执行查询时使用,并不在返回结果中显示,而字段别名会在客户端显示
- 别名包含空格时使用引号包裹别名
1 | -- 为字段指定别名 |
别名示例
1 | -- 创建实验数据表 |
1 | -- 指定字段别名 |
指定条件
运算符
| 运算符 | 描述 |
|---|---|
>,<,>=,<=,=,<> |
大于、小于、大于等于、小于等于、不等于 |
IN(元素) |
包含集合中某个元素 |
IS NULL |
值为NULL |
and、&& |
与,多个条件都要成立 |
or、双管道符 |
或,只要条件成立一个 |
not、! |
不为,取反值 |
语法
1 | select 字段1,字段2 from 表名 where 条件 |
查询指定值
1 | -- 原始数据 |
1 | -- 查询username字段中数据为admin的所有数据 |
1 | -- 查询username字段中数据不为admin的所有数据 |
1 | -- 根据id字段查询前面两个用户数据 |
满足多条件
1 | -- 查询username字段数据为admin且password字段数据为123的所有数据 |
满足一个或以上条件
1 | -- 查询username字段数据为admin或password字段数据为123的所有数据 |
集合元素
1 | -- 查询username字段数据为admin或guest或aaa的所有数据 |
查询NULL值
1 | -- 查询email字段数据为null的所有数据(不能使用=) |
模糊查询
占位符
| 占位符 | 描述 |
|---|---|
_ |
单个字符 |
% |
多个字符 |
语法
1 | select 字段1,字段2 from 表名 where 字段名 like 字符 |
查询示例
1 | -- 原始数据 |
1 | -- 查询username字段数据中以a开头的所有数据 |
排序查询
语法
1 | select 字段1,字段2 from 表名 order by 字段名 ASC; -- 根据指定字段进行升序排序(默认) |
查询示例
1 | -- 根据id字段对查询的数据进行升序排序 |
分组函数
函数
- 分组函数的计算自动排除NULL值
- 分组函数不能直接使用在
where语句中 - 分组函数需要分组之后才能使用,默认一整张表为一组
| 函数 | 描述 |
|---|---|
| count() | 计算个数 |
| max() | 计算最大值 |
| min() | 计算最小值 |
| sum() | 计算和 |
| avg() | 计算平均值 |
查询示例
1 | -- users表数据 |
1 | -- 统计users表的email字段共有几条数据(自动排除NULL) |
分组查询
语法
select语句中如果使用了group by,则select后面只能跟参加分组的字段与分组函数,其他一律不能跟!!!
1 | -- 对数据表按照指定字段进行分组 |
执行顺序
1 | -- 语法(只能按这个顺序写,不可颠倒) |
where与having区别
where在分组查询前进行限定,不满足条件则不参与分组,不能使用聚合函数having在分组之后进行限定,不满足条件则不会被查询出来,可以使用聚合函数- 优化策略: 能用
where实现的就使用where,实现不了就使用having
查询示例
1 | -- 创建销售记录表并插入数据 |
1 | -- 查询销售员共卖了多少产品(根据name字段分组) |
分页查询
语法
- 索引从0开始
- 不指定起始索引时,起始索引默认为0
1 | select 字段1,字段2 from 表名 limit 起始索引,查询条数; |
查询示例
1 | -- users表数据 |
1 | -- 从索引0开始,查询两条数据(0~1) |
联合查询
语法
union将多个查询的结果拼接在一起union在进行合并接结果集时,要求两个结果集的字段数相同- 使用
union比join效率高
1 | -- 不包括重复数据 |
查询示例
1 | -- 创建实验数据 |
1 | -- 联合查询结果(将student表与teacher表的查询结果放一起) |
多表连接查询
概念
多表连接
- 内连接获取多表的重合部分
- 左连接获取左表全部,右表与左表重合部分
- 右连接获取右表全部,左右与右表重合部分
- 任何一个右连接都有左连接的写法,任何一个左连接都有右连接的写法
| 连表方式 | 描述 |
|---|---|
| inner join | 内连接,获取两个表中字段匹配关系的记录,可以省略inner关键词 |
| left join | 左连接,获取左表的所有记录,即使右表没有对应匹配的记录 |
| right join | 右连接,获取右表的所有记录,即使左表没有对应匹配的记录 |
笛卡尔积现象
- 当两张表进行连接查询,没有任何条件限制的时候,最终查询到的结果条数为两张表条数的乘积,该现象被称为
笛卡尔积现象 - 在连接时加上条件,满足条件的记录会被筛选出来,就可以避免笛卡尔积现象
创建数据
1 | -- 学生表 |

内连接
- 得到左表与右表的共同信息
语法
1 | -- 两个表 |
两表查询
- 将
student表别名设置为s,class_order表别名设置为co - 将
s表的stu_id字段与co表的stu_id字段关联 - 查询的结果为两表的共同信息,
s表的stu_id字段与co表的stu_id字段没有同时拥有1004,所以没有1004行结果
1 | -- 查询左表、右表的共同信息 |
三表查询
- 查询学生姓名、科目、成绩
- 第一次内查询将
student表与class_order表通过stu_id字段关联 - 将得到的查询结果再与
class表的class_id关联起来
1 | -- 第一次内连接查询结果 |
左连接
- 得到左表的所有信息与右表的共同信息
语法
1 | -- 两个表 |
两表查询
- 左表
student设置别名为s,右表class_order设置别名为co - 左表与右表的共同字段为
stu_id,所以条件指定s.stu_id=co.stu_id - 左查询结果为左表的全部字段,右表与左表共同信息字段
- 右表没有数据时查询结果为null
1 | -- 查询左表所有字段,右表与左表共同信息 |
三表查询
- 查询学生姓名、科目、成绩
- 第一个左查询将左表
student与右表class_order通过stu_id关联起来 - 第二个左查询将第一个左查询的结果作为左表,与右表
class通过class_id关联起来
1 | -- 第一次左查询结果(通过stu_id关联) |
右连接
- 与左连接相反,得到右表的所有信息与左表的共同信息
语法
1 | -- 两个表 |
两表查询
- 左表
class_order设置别名为co,右表class设置别名为c - 左表与右表的共同字段为
class_id,所以条件指定co.class_id=c.class_id - 右查询结果为右表的全部字段,左表与右表共同信息字段
- 左表没有数据时查询结果为
null
1 | -- 查询右表所有字段,左表与右表共同信息 |
三表查询
- 查询学生姓名、科目、成绩
- 第一个右查询将左表
class_order与右表class通过class_id关联起来 - 第二个右查询将第一个右查询的结果作为左表,与右表
student通过stu_id关联起来
1 | -- 第一次右查询结果 |
子查询
概念
- 子查询是指一个查询语句里面嵌套另一个查询语句内部的查询
- 在执行查询语句时,会先执行子查询中的语句,再将返回结果作为外层查询的过滤条件
语法
1 | -- where后的子查询 |
查询示例
创建实验表
1 | -- 学生表 |
带比较符的子查询
1 | -- 查询谁没有成绩 |
带EXISTS的子查询
ESISTS关键词后面的参数可以是任意的子查询,执行后有值返回TRUE,没值返回FALSE- 当返回值为
TRUE时才会执行外层的查询
1 | -- 如果张三有成绩就返回所有人的信息 |
带ANY的子查询
ANY表示满足其中一个条件就返回一个结果作为外层查询条件
1 | -- 查询 |
带ALL的子查询
约束
约束
| 约束 | 描述 |
|---|---|
| primary key | 主键约束 |
| not null | 非空约束 |
| unique | 唯一约束 |
| foreign key | 外键约束 |
主键约束
- 非空且唯一
- 一张表只能有一个字段为主键
- 主键就是表中记录的唯一标识
创建表时添加主键约束
1 | -- 语法 |
删除主键
1 | -- 语法 |
创建完成表后指定主键
1 | -- 语法 |
自增长
- 如果某字段为数值类型时,可以使用
auto_increment指定该列的值自动增长
1 | -- 创建表时指定某字段数值为自增长 |
1 | -- 表创建后指定某字段数值为自增长 |
1 | -- 删除自增长 |
非空约束
- 值不能为null值,但可以为空格
- 创建完成表后添加非空字段时,该字段下的数据不能为null值
创建表时添加非空约束
1 | -- 语法 |
删除非空约束
1 | -- 语法 |
创建完表后添加非空约束
1 | -- 语法 |
唯一约束
- 值不能重复,但可以有多个null值
创建表时添加唯一约束
1 | -- 语法 |
删除唯一约束
1 | -- 语法 |
创建表后添加唯一约束
1 | -- 语法 |
外键约束
介绍
- 外键: 外键是表的一个特殊字段,被参照的表是主表,外键所在的字段的表为子表
- 原则: 外键的原则是依赖于数据库中已存在的表的主键
- 作用: 外键作用是建立子表与父表的关联关系,父表中对记录做出操作时,子表对应的信息也应有相应的改变,从而保持数据的一致性与完整性
注意事项
- 父表和子表必须使用相同的存储引擎,并且禁止使用临时表
- 数据表的存储引擎只能是InnoDB
- 外键列和参照列必须具有相似的数据类型。其中数字长度或是否有符号必须相同,而字符的长度可以不同
- 外键列和参照列必须创建索引,如果外键列不存在索引时,MySQL将自动创建索引
- 子表外键引用父表的某个字段,被引用的字段不一定要为主键,但一定要具有唯一性(unique约束)
创建删除顺序
- 创建表: 先创建父表再创建子表
- 删除表: 先删除子表再删除父表
- 删除数据: 先删除子表再删父表
- 插入数据: 先插父表再插入子表
外键约束
| 关键词 | 描述 |
|---|---|
| CASCADE | 父表删除或更新,子表也会删除或更新匹配的行 |
| SET NULL | 父表删除或更新,子表的外键值会设置为NULL (子表字段不能指定not null) |
| RESTRICT | 拒绝对父表的删除或更新 |
语法
1 | -- 创建表时添加外键 |
创建表时指定外键
1 | -- 创建数据表 |
1 | -- 查看表数据 |
使用外键约束后,想插入或修改外键约束字段的内容时,修改或插入的值只能来源于父表class的c_id字段的内容,这就保证了数据的安全性与统一性
1 | -- 值1002在父表的c_id字段中,允许添加或更新 |
如果还是要插入该字段的内容则需要在父表中先插入对应数据,再插入子表数据
1 | -- 插入父表数据 |
删除父表数据时需要先删除子表外键对应的数据
1 | -- 直接删除父表数据,失败 |
常用函数
日期转换
创建实验表
1 | drop tables if exists users; |
str_to_date
将字符串类型转换为date类型,通常使用在insert插入数据
1 | -- 语法 |
date_format
将date类型转换为字符串类型,通常使用在select查询日期
1 | -- 语法 |
日期时间
创建实验表
1 | drop tables if exists users; |
插入日期时间
1 | -- 默认格式: %Y-%m-%d %h:%i:%s |
now
获取系统当前日期时间
1 | -- 格式 |
current_time
获取当前系统时间
1 | -- 格式 |
current_date
获取当前系统日期
1 | -- 格式 |
unix_timestamp
将日期转换为时间戳
1 | -- 语法 |
时间差
语法
1 | -- 语法 |
示例
1 | -- 查询2000-01-01到2022-01-01相差几年 |
1 | -- 查询2000-06-01年出生的现在几岁了(当前日期2022-03-18) |
事务
概念
概念
- 一个事务就是一个完整的业务逻辑,是一个最小的工作单元
- MySQL事务主要用于处理操作量大、复杂度高的数据
- 事务只支持存储引擎为InnoDB的库或表
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行要么全部不执行
- 事务可以用来管理insert、update、delete语句(DML操作)
- 事务在执行过程中每条DML操作都会记录到事务性活动的日志文件中
- 提交事务会清空事务性活动的日志文件,将数据全部持久化到数据库表中,事务全部成功结束
- 回滚事务将之前的DML操作全部撤销且清空事务性活动日志,事务全部失败结束
- MySQL默认每执行一条DML语句则自动提交事务
事务的特征
- 原子性: 事务时不可分割的最小操作单位,要么同时成功,要么同时失败
- 持久性: 当事务提交或回滚后,数据库会持久化存储该数据
- 隔离性: 多个事务之间互相独立
- 一致性: 事务操作前后数据总量不变
提交与回滚
语法
1 | -- 打开事务(关闭自动提交机制) |
默认提交事务
MySQL默认每执行一条DML语句则会自动提交一次事务,所以回滚后还是提交后的数据
1 | -- 创建数据表后插入数据 |
开启事务(关闭自动提交)
当开启事务后,对数据进行增、删、改,在未提交数据前进行回滚,都能回到上一步
1 | -- 开启事务(关闭自动提交) |
对数据进行修改后提交事务,数据无法恢复
1 | -- 再次删除数据 |
事务隔离
事务的四个隔离级别
- 读未提交: 事务A可以读到事务B未提交的数据,该隔离级别存在脏读现象(读到脏数据),该隔离级别一般都是理论上的,不常用
- 读已提交: 事务A只能读到事务B提交后的数据,该隔离级别解决了脏读现象,但不可重复读取数据
- 可重复读: 事务A开启后不管多久,在每一次事务A中读取到的数据都是一致的。即使事务B将数据修改并提交了,事务A读取到的数据还是没有发生改变。该隔离级别解决了不可重复读的问题,但可能出现幻影读(每次读到的数据都是幻象,不够真实)
- 序列化读: 该隔离级别表示事务排队,不能并发(效率低)。但解决了上方的所有问题,每次读取到的数据都是最真实的
| 隔离 | 描述 |
|---|---|
| read uncommitted | 读未提交(最低隔离级别) |
| read committed | 读已提交 |
| repeatable read | 可重复读(MySQL默认) |
| serializable | 序列化/串行化(最高隔离级别) |
设置事务隔离级别
1 | -- 查看当前事务隔离级别 |
读未提交
- 默认没有提交时事务A做修改但未提交,则事务B是读取不到事务A未提交的内容
- 开启
read uncommitted事务隔离时,事务A做修改但未提交,则事务B可以看到事务A未提交的内容
1 | -- 窗口0 (设置全局事务隔离级别) |
1 | -- 窗口1 (事务A) |
1 | -- 窗口2 (事务B) |
读已提交
- 当事务A修改数据后未提交,事务B看不到事务A未提交的值
- 当事务A提交数据后,事务B才能看到事务A提交的值
1 | -- 窗口0 (设置全局事务隔离级别) |
1 | -- 窗口1 (事务A) |
1 | -- 窗口2 (事务B) |
1 | -- 窗口1 (事务A) |
可重复读
- 事务A修改数据并提交后,事务B看到的数据还是事务A修改前的旧数据
- 事务B退出重新登录后,看到的是事务A修改提交后的新数据
- 再开启一个新的终端看到的也是事务A修改提交后的新数据
1 | -- 窗口0 (设置全局事务隔离级别) |
1 | -- 窗口1 (事务A) |
1 | -- 窗口2 (事务B) |
序列化读
- 当事务A对
users表进行修改且未提交时,事务B对users表进行查询或其他操作时都会卡在等待界面 - 当事务A提交事务后,事务B才可以对事务A操作的表进行查询或修改
1 | -- 窗口0 (设置全局事务隔离级别) |
1 | -- 窗口1 (事务A) |
1 | -- 窗口2 (事务B) |
1 | -- 窗口1 (事务A) |
索引
概念
概念
- 索引是在数据库表的字段上添加的,是为了提高查询效率而存在的一种机制
- 一张表的一个字段可以添加一个索引,多个字段联合也可以添加索引
- 索引相当于书的目录,是为了缩小扫描范围而存在的一种机制
- 如果没有添加索引,MySQL会进行全扫描,效率较低。添加索引后通过索引定位到大概位置,再进行局域性扫描,效率较高
- 任何数据库中主键上都会自动添加索引对象,在MySQL数据库表字段中有
unique约束也会自动创建索引
索引类型
- 单一索引: 在一个字段上添加索引
- 复合索引: 在多个字段上添加索引
- 主键索引: 在主键上添加索引
- 唯一索引: 在
unique约束字段添加索引,字段内容越唯一效率越高
实现原理
- 在MySQL中索引是一个单独的对象,不同的存储引擎以不同的形式存在
- 索引在MySQL中都是以一棵树的形式存在(自平衡二叉树
B-Tree) - 索引字段的每行数据在硬盘上都有物理存储编号
1 | -- users表,假设存储编号如下(存储编号存储在物理磁盘) |
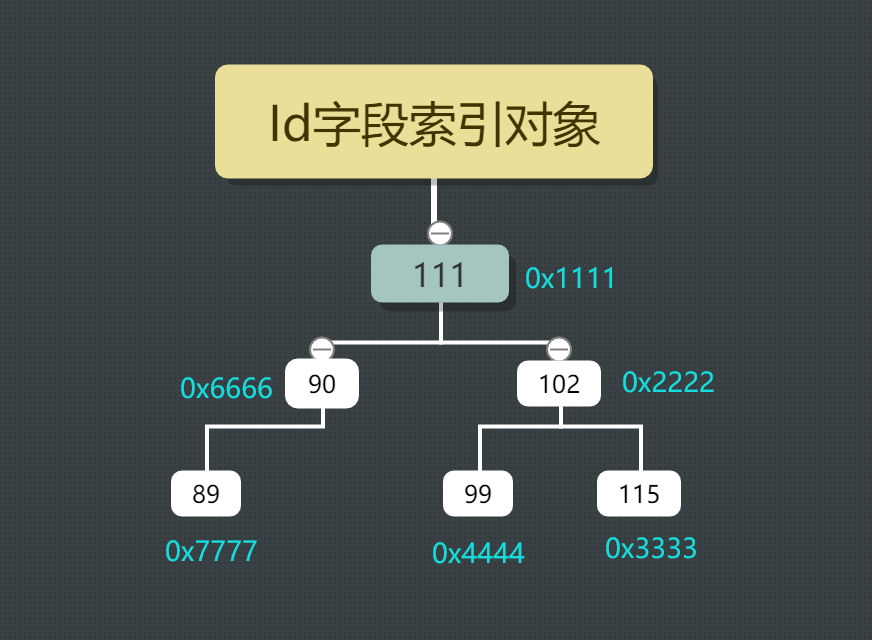
何时添加索引
- 数据量庞大(具体看硬件环境来定义数据量)
- 索引字段经常出现在
where后,以条件的形式存在(该字段经常被扫描) - 该字段很少有增、删、改操作,因为DML之后索引需要重新排序
- 不要随意添加索引,因为索引需要维护,太多反而会降低系统性能,建议通过主键或unique约束的字段进行查询
创建删除索引
语法
1 | -- 创建索引 |
创建索引
- 当
type=ALL时表示全表扫描,rows=4表示扫描了4次才拿到数据 - 当
type=ref时表示使用索引,rows=1表示扫描了1次就拿到数据
1 | -- 创建实验表 |
1 | -- 未使用索引时 (type=ALL) |
1 | -- 使用索引 (type=ref) |
删除索引
1 | -- 删除字段索引(type=ALL) |
索引的失效
失效原因
- 使用模糊查询时尽量不要以
%开始,否则索引会失效 - 使用
or时两边条件字段都要有索引,否则索引失效 - 可以使用
union来替换or进行查询,索引不会失效 - 在
while中索引字段参加了运算,索引失效 - 在
while中索引字段使用了函数,索引失效 - 使用复合索引时未使用左侧列查找(最左原则),索引失效
代码示例
1 | -- 创建索引 |
视图
概念
- 站在不同的角度操作同一份数据
- 对视图进行增删改查时,会导致原表的数据被操作(视图的特性)
- 视图在开发中起到方便、简化开发、利于维护的作用
- 对于需要经常使用且非常复杂的SQL语句,可以使用视图对象来简化开发
- 操作视图就像操作表一样,视图存储在硬盘当中
- 创建视图时对应的语句只能是查询语句,视图创建后可以对视图进行增删改查
使用视图
语法
1 | -- 创建视图 |
代码示例
1 | -- 原表数据 |
数据库设计
概念
设计三范式
- 任何一张表必须有主键,每一个字段原子性不可再分
- 所有非主键字段完全依赖主键 (建立在第一范式基础之上)
- 所有非主键字段直接依赖主键 (建立在第二范式基础之上)
按照三范式进行设计的数据库,可以避免表中数据冗余,浪费空间
总结
- 数据库设计三段式是理论上的,实践与理论有偏差
- 有时候会拿冗余换执行速度,因为表与表连接次数越多,效率越低
- 空间足够可以不用考虑冗余,减少表与表的连接次数
- 对于开发人员来说,sql语句的编写难度也会降低
第一范式
未满足第一范式的数据表
- 该数据表没有主键
- 该数据表
联系方式字段还可以再分割
1 | 用户编号 用户姓名 联系方式 |
修改后
- 为
用户编号创建主键 - 将联系方式分割成多个字段(原子性不可再分割)
1 | 用户编号(pk) 用户姓名 邮箱 电话 |
第二范式
未满足第二范式的数据表
- 学生编号与教师编号两个字段做复合主键
- 但
学生姓名依赖学生编号,教师姓名依赖教师编号,所以并没有完全依赖主键(部分依赖) - 部分依赖导致了数据冗余与空间浪费
1 | -- 不满足第一范式 |
修改后
- 使用三张表来表示多对多关系(学生表、教师表、学生教师关系表)
- 将编号与id字段设置为主键,将关系表的字段设置为外键连接到教师表与学生表
口诀: 多对多,三张表,关系表两个外键
1 | -- 学生表 |
第三范式
未满足第三范式的数据表
班级名称依赖班级编号,班级编号依赖学生编号,产生传递依赖所以不满足第三范式
1 | -- 满足第二范式,但不满足第三范式 |
修改后
- 将数据表拆分为两个表(班级表、学生表)
- 将学生表的
班级编号外键到班级表的班级编号
口诀: 一对多,两张表,多的表加外键
1 | -- 班级表 |
权限系统
注意点
- 下方数据库版本为
5.7,其他版本语法可能不一样!!! - 对用户进行操作时最好使用
root用户 - 修改用户权限时一定要刷新系统表
- 修改用户权限后要退出重新登录再测试权限
创建用户
语法
1 | -- 主机为%时表示允许任何主机登录 |
示例
- 创建用户名为
test密码为123456的用户,该用户允许从任何主机登录
1 | mysql> create user 'test'@'%' identified by '123456'; |
授权用户
语法
- 如果允许用户对指定数据库的所有表进行操作就写 数据库
.* - 如果允许用户对所有数据库的所有表进行操作就写
*.* - 修改权限后要退出重新登录才会生效
1 | -- 查看用户权限 |
1 | -- 权限 |
示例
- 创建
user1用户,密码为123456,允许所有主机登录,允许该用户对所有数据库进行任何操作
1 | grant all privileges on *.* to 'user1'@'%' identified by '123456'; |
- 将
test用户权限改为对所有数据库仅有select、update权限
1 | grant select,update on *.* to 'test'@'%' with grant option; |
权限回收
语法
1 | -- 权限同授权时的权限 |
示例
- 回收
user1用户的全部权限
1 | revoke all privileges on *.* from 'user1'@'%'; |
- 回收
test用户对test数据库的update权限
1 | -- 就取走update权限,其他还在 |
修改密码
语法
1 | set password for '用户名'@'主机' = password('新密码'); |
示例
- 将
test用户密码改为12321
1 | mysql> set password for 'test'@'%' = PASSWORD('123321'); |
删除用户
语法
1 | drop user '用户名'@'主机' |
示例
- 删除
test用户
1 | -- 删除test用户 |
导入导出
导出数据库
语法
1 | # 导出整个数据库 |
创建实验数据库
1 | create database output_input; |
导出整个数据库
1 | # 包含数据,导出到当前工作目录下 |
导出数据库的一个表
1 | # 包含数据,导出到当前工作目录下 |
导入数据库结构
1 | # 不包含数据,导出到当前工作目录下 |
导入数据库
语法
1 | # 要提交创建数据库 |
1 | -- 要提交创建数据库,使用source指定sql文件 |
示例
1 | -- 使用方法1导入 |
 wechat
wechat alipay
alipay